THE CUSTOMIZATION CONUNDRUM
Fine-Tuned models differentiate, but make generation harder.
Generative AI is most useful when it's fine-tuned for a specific person or style. You may need hundreds or thousands of different model versions, and need inference done on any one at random. Keeping this many models organized is difficult and inference requires loading and unloading the models on the GPU server whenever the customer makes a request.
Model Management
To generate images, text, or video that look or sound like your customer, you will need to create, store, and manage tens or hundreds of thousands of model versions.
On-Demand Inference
Keeping 100,000 different models online 24/7 is cost prohibitive. You need to be able to run inference with a given model only when that customer makes a request.
Scalable Fine-Tuning
Creating fine-tuned models for customers takes significantly longer than inference. You need to be able to run 100s of fine-tuning tasks in parallel to on-board customers quickly.
Affordable Infrastructure
Competition is already fierce. You need to ensure your infrastructure cost doesn't destroy your product's viability.
Serverless GPU infrastructure
proxiML's serverless infrastructure platform makes easy and affordable to host customized, large-scale generative AI services.
SEE FOR YOURSELF
Try our generative AI tutorials.
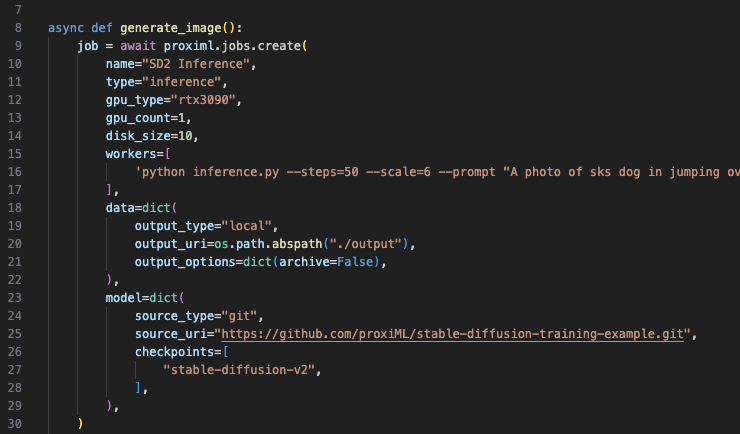
Stable Diffusion 2 Generation
Use proxiML Notebooks, Inference Jobs, and Endpoints to run text-to-image and image-to-image generations with Stable Diffusion 2.
Try It Out
Training and Deploying a Custom Stable Diffusion Model
Use the proxiML platform to personalize a stable diffusion version 2 model on a subject using DreamBooth and generate new images.
Try It Out
LLaMA/Alpaca Training
Use the Stanford Alpaca code to fine-tune a Large Language Model (LLM) as an instruction-trained model and use the results for inference on the proxiML platform.
Try It Out
TURNKEY HYBRID/MULTICLOUD
As your usage increases, use CloudBender™ to onboard your own cloud or physical GPU resources to save even more money. You won't have to change your code or pipeline at all.