Deploy Accelerated AI to the Edge
Easily manage fleets of accelerated IoT devices for real-time inference at the edge.

Easy On-Boarding
Devices ship with the proxiML operating system preinstalled. Devices are configured automatically in a matter of minutes.Centralized Management
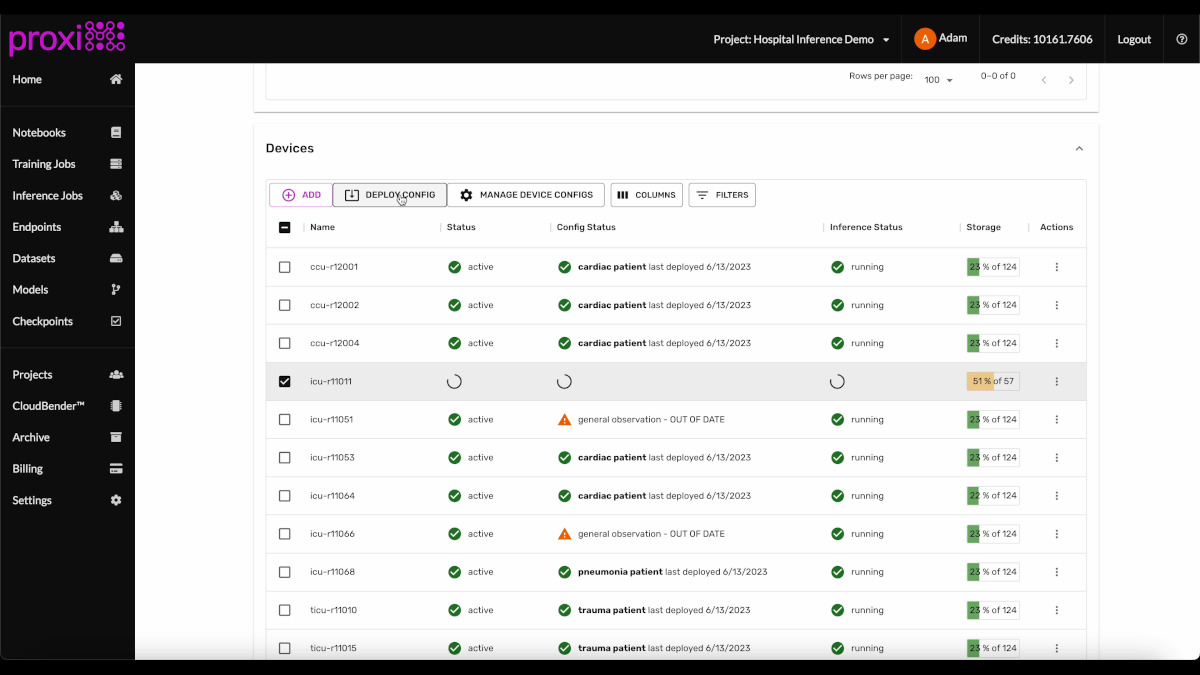
Manage 1000s of devices centrally. Mass-deploy configuration updates with a click of a button.Workload Agnostic
Whether you're doing video processing in Python or sensor processing in Rust, proxiML can deploy any application to your devices.
Machine Learning on IoT is different
IoT fleet management is hard, but running deep learning workloads on GPU-enabled devices like NVIDIA Jetson adds a host of other demands. The proxiML platform handles these unique challenges automatically.
The ML-first platform.
proxiML makes it easy to deploy and manage deep learning workloads to GPU-enabled edge devices. We handle everything from OS patching to driver installation to workload monitoring.
- Automated model deployment
Advanced vision models can be 10GB+. The proxiML platform storage engine makes it easy to deploy large model revisions to 1000s of devices in parallel.
- Monitoring and alerting
Device telemetry and availability monitoring is automatically configured for every device and region. Get alerted when devices are offline out out-of-date.
- Integration with on-prem services
Many edge inference applications need to access additional data for predictions or store results locally in customer systems. proxiML lets you configure these centrally and securely.
EDGE GPU PLATFORM